Create a dataset and add examples
The following sections explain the different ways you can create a dataset in LangSmith and add examples to it. Depending on your workflow, you can manually curate examples, automatically capture them from tracing, import files, or even generate synthetic data:- Manually from a tracing project
- Automatically from a tracing project
- From examples in an Annotation Queue
- From the Prompt Playground
- Import a dataset from a CSV or JSONL file
- Create a new dataset from the dataset page
- Add synthetic examples created by an LLM via the Datasets UI
Manually from a tracing project
A common pattern for constructing datasets is to convert notable traces from your application into dataset examples. This approach requires that you have configured tracing to LangSmith.A technique to build datasets is to filter the most interesting traces, such as traces that were tagged with poor user feedback, and add them to a dataset. For tips on how to filter traces, refer to Filter traces guide.
-
Multi-select runs from the runs table. On the Runs tab, multi-select runs. At the bottom of the page, click Add to Dataset.

-
On the Runs tab, select a run from the table. On the individual run details page, select Add to -> Dataset in the top right corner.


Automatically from a tracing project
You can use run rules to automatically add traces to a dataset based on certain conditions. For example, you could add all traces that are tagged with a specific use case or have a low feedback score.From examples in an Annotation Queue
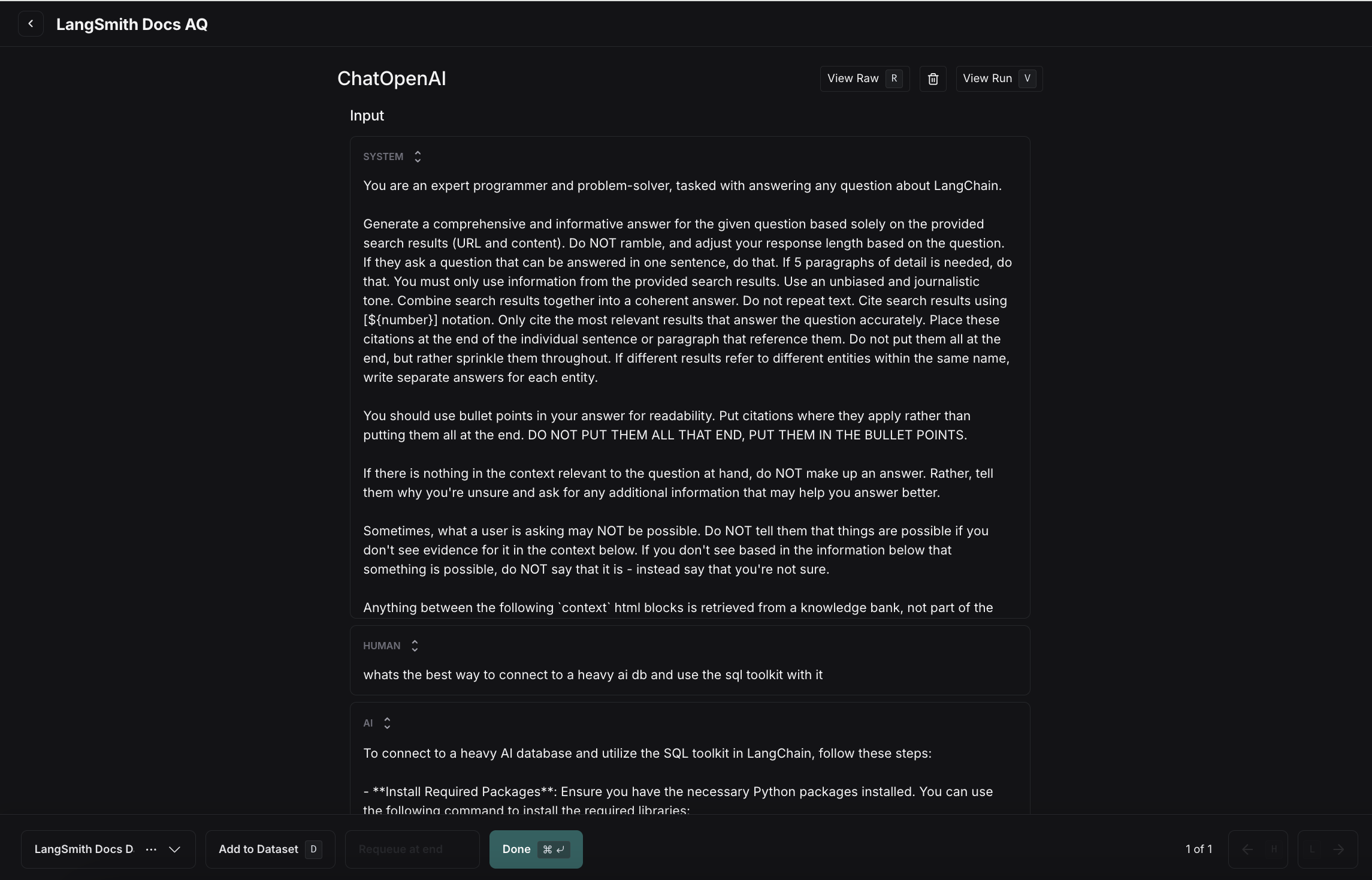
If you rely on subject matter experts to build meaningful datasets, use annotation queues to provide a streamlined view for reviewers. Human reviewers can optionally modify the inputs/outputs/reference outputs from a trace before it is added to the dataset.
D to add the run to it.
Any modifications you make to the run in your annotation queue will carry over to the dataset, and all metadata associated with the run will also be copied.
From the Prompt Playground
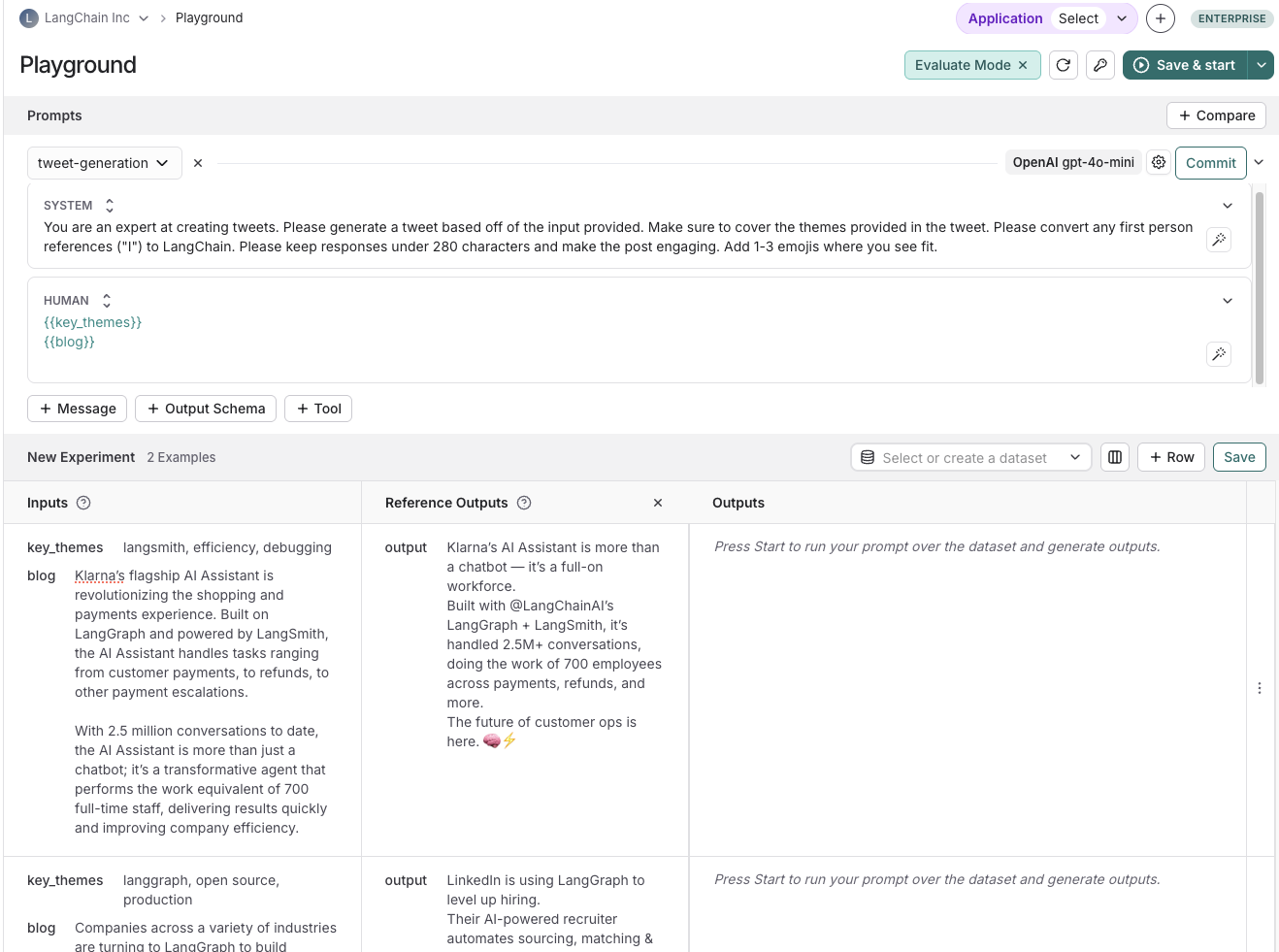
On the Prompt Playground page, select Set up Evaluation, click +New if you’re starting a new dataset or select from an existing dataset.Creating datasets inline in the playground is not supported for datasets that have nested keys. In order to add/edit examples with nested keys, you must edit from the datasets page.
- Use +Row to add a new example to the dataset
- Delete an example using the ⋮ dropdown on the right hand side of the table
- If you’re creating a reference-free dataset remove the “Reference Output” column using the x button in the column. Note: this action is not reversible.
Import a dataset from a CSV or JSONL file
On the Datasets & Experiments page, click +New Dataset, then Import an existing dataset from CSV or JSONL file.Create a new dataset from the Datasets & Experiments page
- Navigate to the Datasets & Experiments page from the left-hand menu.
- Click + New Dataset.
- On the New Dataset page, select the Create from scratch tab.
- Add a name and description for the dataset.
- (Optional) Create a dataset schema to validate your dataset.
- Click Create, which will create an empty dataset.
- To add examples inline, on the dataset’s page, go to the Examples tab. Click + Example.
- Define examples in JSON and click Submit. For more details on dataset splits, refer to Create and manage dataset splits.
Add synthetic examples created by an LLM
If you have existing examples and a schema defined on your dataset, when you click + Example there is an option to Add AI-Generated Examples. This will use an LLM to create synthetic examples. In Generate examples, do the following:- Click API Key in the top right of the pane to set your OpenAI API key as a workspace secret. If your workspace already has an OpenAI API key set, you can skip this step.
- Select : Toggle Automatic or Manual reference examples. You can select these examples manually from your dataset or use the automatic selection option.
- Enter the number of synthetic examples you want to generate.
-
Click Generate.

- The examples will appear on the Select generated examples page. Choose which examples to add to your dataset, with the option to edit them before finalizing. Click Save Examples.
-
Each example will be validated against your specified dataset schema and tagged as synthetic in the source metadata.



Manage a dataset
Create a dataset schema
LangSmith datasets store arbitrary JSON objects. We recommend (but do not require) that you define a schema for your dataset to ensure that they conform to a specific JSON schema. Dataset schemas are defined with standard JSON schema, with the addition of a few prebuilt types that make it easier to type common primitives like messages and tools. Certain fields in your schema have a+ Transformations option. Transformations are preprocessing steps that, if enabled, update your examples when you add them to the dataset. For example the convert to OpenAI messages transformation will convert message-like objects, like LangChain messages, to OpenAI message format.
For the full list of available transformations, see our reference.
If you plan to collect production traces in your dataset from LangChain ChatModels or from OpenAI calls using the LangSmith OpenAI wrapper, we offer a prebuilt Chat Model schema that converts messages and tools into industry standard openai formats that can be used downstream with any model for testing. You can also customize the template settings to match your use case.Please see the dataset transformations reference for more information.
Create and manage dataset splits
Dataset splits are divisions of your dataset that you can use to segment your data. For example, it is common in machine learning workflows to split datasets into training, validation, and test sets. This can be useful to prevent overfitting - where a model performs well on the training data but poorly on unseen data. In evaluation workflows, it can be useful to do this when you have a dataset with multiple categories that you may want to evaluate separately; or if you are testing a new use case that you may want to include in your dataset in the future, but want to keep separate for now. Note that the same effect can be achieved manually via metadata - but we expect splits to be used for higher level organization of your dataset to split it into separate groups for evaluation, whereas metadata would be used more for storing information on your examples like tags and information about its origin. In machine learning, it is best practice to keep your splits separate (each example belongs to exactly one split). However, we allow you to select multiple splits for the same example in LangSmith because it can make sense for some evaluation workflows - for example, if an example falls into multiple categories on which you may want to evaluate your application. In order to create and manage splits in the app, you can select some examples in your dataset and click “Add to Split”. From the resulting popup menu, you can select and unselect splits for the selected examples, or create a new split.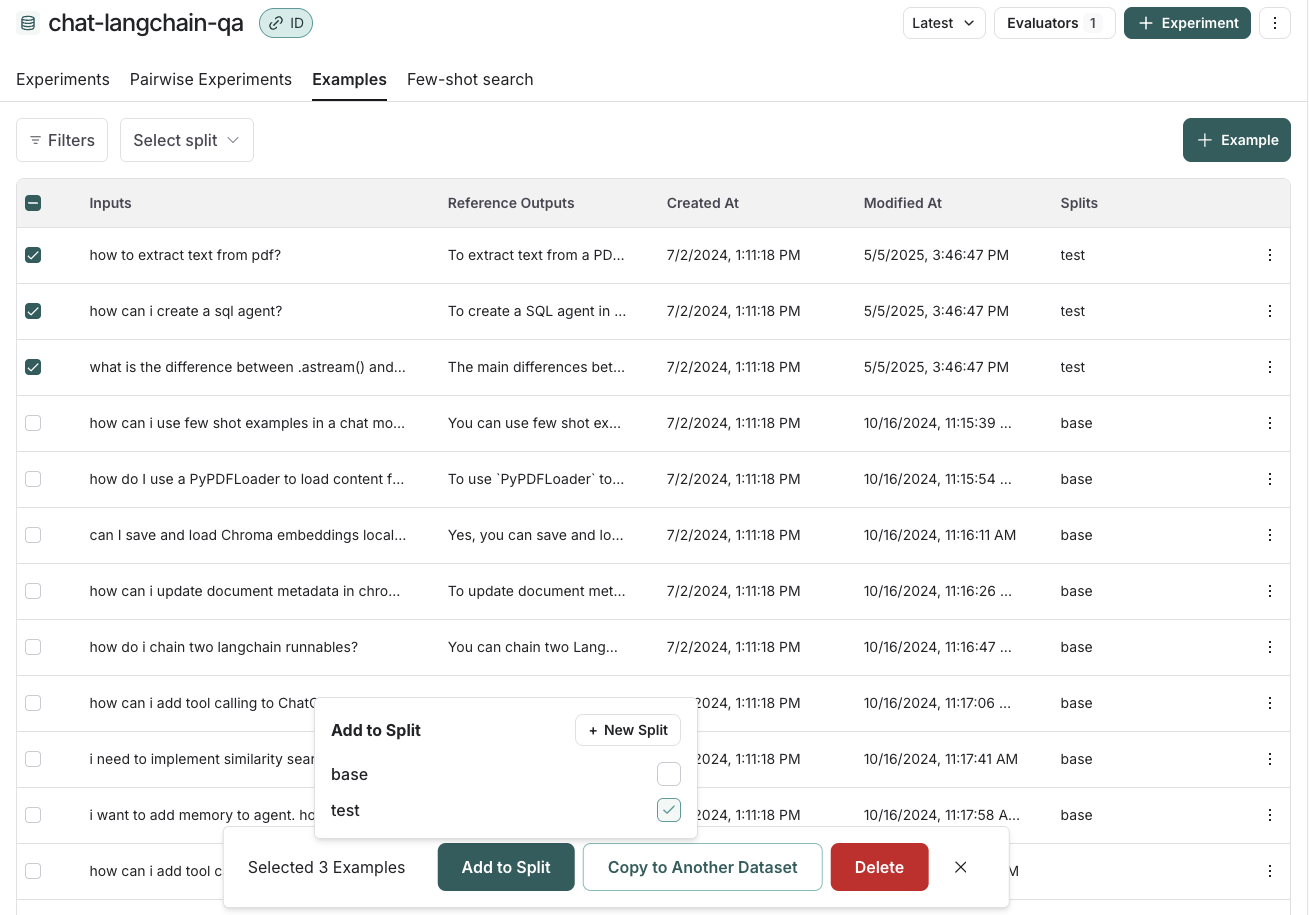
Edit example metadata
You can add metadata to your examples by clicking on an example and then clicking “Edit” on the top righthand side of the popover. From this page, you can update/delete existing metadata, or add new metadata. You may use this to store information about your examples, such as tags or version info, which you can then group by when analyzing experiment results or filter by when you calllist_examples in the SDK.

Filter examples
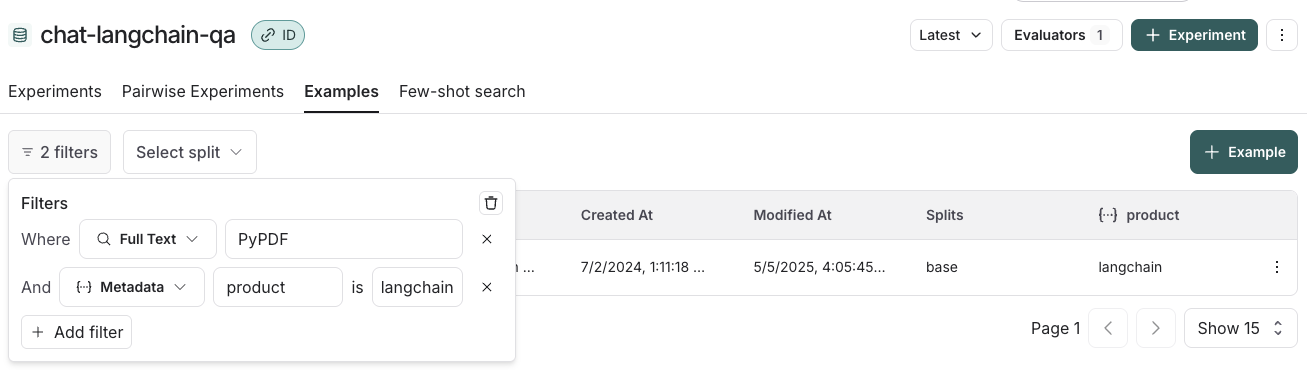
You can filter examples by split, metadata key/value or perform full-text search over examples. These filtering options are available to the top left of the examples table.- Filter by split: Select split > Select a split to filter by
- Filter by metadata: Filters > Select “Metadata” from the dropdown > Select the metadata key and value to filter on
- Full-text search: Filters > Select “Full Text” from the dropdown > Enter your search criteria